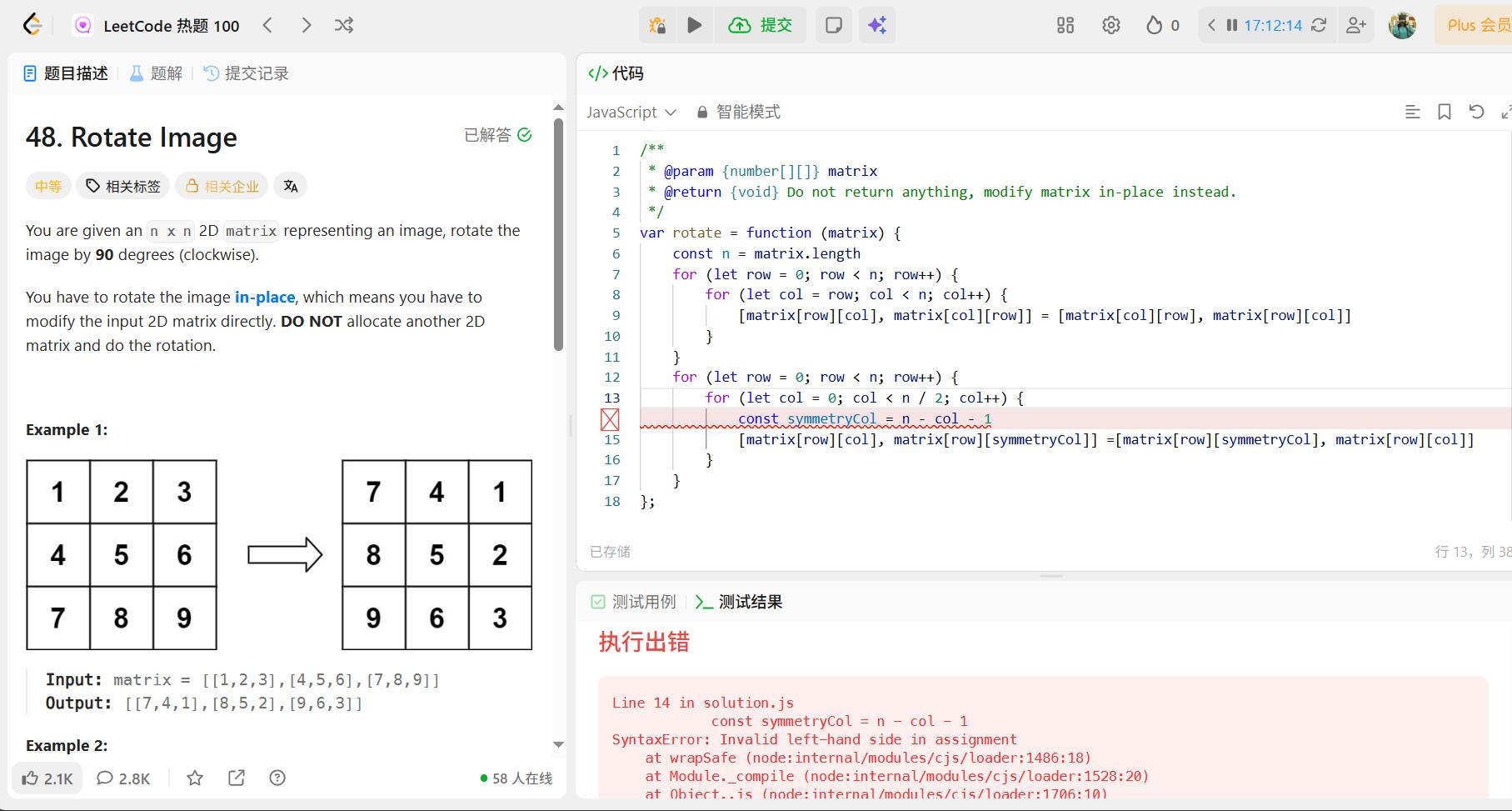
首先,如上图所示,我是一个JS无分号派,此前也没因此遇到问题;
然后,写这道题的时候就遇到问题了;没错,正是因为那一行没加分号。
为什么这里缺少分号会报错呢,什么情况下JS代码不加分号会报错?
为什么有的语言需要分号、有的不需要?
总的来说:分号是语句终止信号的一种形式,影响着语句解析;用不用分号是“多写一点换严谨” 还是 “少写一点换效率”的tradeoff。
C及后来被它影响的C++、Java都使用分号来分隔语句,通过显式的符号来简化语法解析。
另一些语言如早期的Lisp家族、后来的python、JS、GO都不需要分号,其中又可以分为两类:(1) 用其他语法来判断语句边界,如Lisp家族用括号来分隔、python用缩进+换行来分隔 (2)用ASI机制来补全分号:如JS在语法分析时补全分号,GO在词法分析阶段就强制插入分号。
ASI是什么
ASI,Automatic Semicolon Insertion,自动分号插入。 JS的编译执行流程是:原始 JS 代码 → 词法分析 → Token → 语法分析 → AST → 解释器/编译器 → 代码执行。Token是对代码进行的第一次处理结果,本质是根据语法将代码拆分为最小且有独立含义的单元(如运算符,变量名/函数名等标识符,let/const等关键字),类似阅读自然语言时拆分成词语。而ASI发生在将token构建成AST的语法分析的过程中,根据一套固定规则判断是否需要在特定位置补充分号,这套规则就是ASI规则。
先来看下这套规则的发展历史(AI梳理的,没挨个查证):
ES1(1997 年):作为 ECMAScript 的首个规范版本,首次引入了自动分号插入的概念,试图定义基本规则来处理缺少分号的语法场景,但规则较为简略,主要针对解析器遇到语法错误时的 "纠错" 行为。
ES3(1999 年):对 ASI 规则进行了重要补充,明确了分号可能被自动插入的三种基本场景:
语句末尾的换行处
程序结束位置
闭合括号
}之前同时首次定义了 "禁止自动插入分号" 的情况(如 for 循环中的表达式分隔)。
ES5(2009 年):进一步细化了 ASI 的判断逻辑,补充了对正则表达式、模板字符串等场景的处理规则,明确了 "no LineTerminator here" 约束(某些位置不允许换行,否则会触发 ASI),使规则更加严谨。
ES6/ES2015(2015 年):随着箭头函数、模块语法等新特性的引入,ASI 规则适配了新语法结构,例如明确了箭头函数
=>前的换行处理、export语句后的分号插入逻辑等。后续版本(ES2016 至今):在保持核心规则稳定的前提下,ASI 规范主要根据新增语法(如动态 import、可选链等)进行边缘场景的适配,未对基础机制做重大调整。
可以看出,ASI 的出发点不是替代分号,而是纠错;它的存在是为了兼容省略分号的写法。
再看下ECMAScript 规范 中关于 ASI 的三条规则:
There are three basic rules of semicolon insertion:
- When, as the source text is parsed from left to right, a token (called the offending token) is encountered that is not allowed by any production of the grammar, then a semicolon is automatically inserted before the offending token if one or more of the following conditions is true:
- The offending token is separated from the previous token by at least one LineTerminator.
- The offending token is
}.- The previous token is
)and the inserted semicolon would then be parsed as the terminating semicolon of a do-while statement (14.7.2).- When, as the source text is parsed from left to right, the end of the input stream of tokens is encountered and the parser is unable to parse the input token stream as a single instance of the goal nonterminal, then a semicolon is automatically inserted at the end of the input stream.
- When, as the source text is parsed from left to right, a token is encountered that is allowed by some production of the grammar, but the production is a restricted production and the token would be the first token for a terminal or nonterminal immediately following the annotation “[no LineTerminator here]” within the restricted production (and therefore such a token is called a restricted token), and the restricted token is separated from the previous token by at least one LineTerminator, then a semicolon is automatically inserted before the restricted token.
感觉非常拗口...尝试理解一下:
规则1是试错行为:遇到语法错误且满足相关条件后会插入分号。这里的核心概念是offending token,可以理解为“语法不允许出现的token”。遇到offending token且满足前面是换行符等条件时,则触发ASI,将自动在该token前加上分号。
|
|
规则2是处理EOF的,解析到文件末尾仍不完整时,补分号收尾。
规则3是强制行为:遇到restricted token但前面有换行符时,将在该token前强制插入分号。restricted token 是 “语法正确但不允许换行的 token” ,规范中称为 No LineTerminator Here,简称 NLTH。如果实际代码中该 token 与前一个 token 之间有换行,则触发 ASI。
restricted token 示例:
return/break/continue后的任何 token;- 后置
++/--前的 token; - 箭头函数
=>
|
|
总结一下大概的判断逻辑:以 “补充分号” 为手段,尽可能让省略分号的代码通过语法解析,但在违反 “禁止换行” 的场景下,会强制插入分号(即使这可能导致最终报错)。
V8里ASI的实现
|
|
先来看换行判断:
|
|
看到这里似乎只要有换行符就会把after_line_terminator设置为true、添加分号,但根据规则1我们知道、下一行token能否与当前内容构成合法语法时时,是不会加分号的,这个判断在哪里?
实际上,相关逻辑四散在 ExpectSemicolon() 的调用里。scan词法分析阶段是不需要这个判断的,因为在parser语法分析阶段,只有语句解析结束后、可能需要插入分号的情况(包括return、break 等 NLTH token后)时才调用ExpectSemicolon()。而“行末和下一行行首构成合法语法”这种情况下(比如我犯的那个错误),解析器会将两行合并为同一表达式,根本不会调用这个函数触发ASI。
再来看下 IsAutoSemicolon() :
|
|
这里的实现还是很有意思的,IsInRange() 是个工具函数,入参是变量、区间上限、区间下限,变量落在区间里时返回true。[kSemicolon, kEos] 是一个连续的整数区间,映射能够触发 ASI 的token值(如规则里提到的} 等);这些整数值和其对应关系是由一个自动化脚本根据文件里定义好的 TOKEN_LIST 来生成的。
换言之,这里用表驱动代替了复杂的多条件判断。
总结
那么JS该不该写分号呢?当行首和上一行行末连接后符合语法规则时,最好手动加分号,即以 (、[、/、+、- 开头的前一行最好都写上分号,一个孤单的分号、突兀的分号;
要么还是每一行都加上吧;

